How We Built Conversational Product Search for E-Commerce
WisdomChat is an AI personal shopper for fashion e-commerce. Here's how we built the five-stage AI pipeline that powers it — from intent classification to hallucination guards.


The Broken State of Product Search
Type "red dress for wedding" into most e-commerce search bars and you'll get results sorted by keyword match, filtered by price range, ranked by sales velocity. You might get the right answer. You probably won't.
The problem isn't the algorithm — it's the model of the shopper. Traditional search assumes someone who knows exactly what they want, expresses it in product-catalogue language, and filters their way to a purchase. Real shoppers aren't like this. They say things like "something my mother-in-law would approve of" or "I need an outfit for my cousin's sangeet but I already wore my pink lehenga last time." No keyword engine understands that sentence.
WisdomChat is an AI personal shopper built to handle exactly that kind of query — conversationally, across multiple turns, with memory of everything the shopper has said. Here's how we built it.
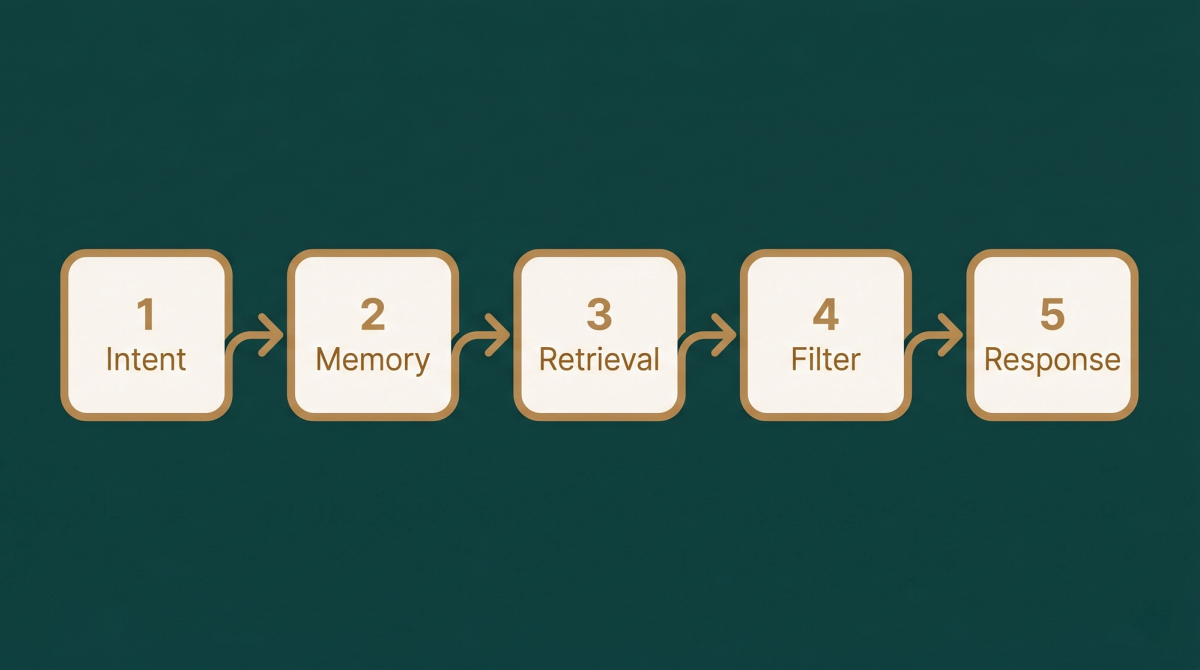
The Architecture: Five Stages, One Conversation
Every message a shopper sends passes through five pipeline stages before a response is generated. Each stage is designed with one principle in mind: do as much as possible without involving the language model, and only call the model when genuinely necessary.
Stage 1: Understanding Intent
The first stage classifies what the shopper is trying to do. We recognise 23 distinct intent types — from direct product requests to size questions, budget constraints, occasion planning, and comparison requests. Getting this right is foundational: every downstream stage depends on knowing what kind of question is being asked.
We built five layers of fallback logic. The primary classifier handles common cases. When confidence falls below a threshold, a secondary regex-based classifier takes over. When a shopper clicks a suggestion chip rather than typing freely, we bypass classification entirely — the intent is already known. An emotion-detection layer runs in parallel, overriding classification when the message tone signals frustration, excitement, or gift-buying anxiety.
Why five layers? Conversational language is deliberately imprecise, and a single classifier trained on clean data will fail on the messiness of real queries. Edge cases aren't edge cases when you're serving hundreds of shoppers a day — they're a meaningful slice of traffic.
Stage 2: Session Context and Memory
A single message rarely tells you enough. The gender of the shopper, their budget ceiling, the occasion they're shopping for, whether they're buying for themselves or as a gift — these details emerge gradually across a conversation, and each one constrains the product search that follows.
We maintain a typed session profile that accumulates across turns. It has explicit fields for budget, gender context, occasion, style preferences, and previously shown products. Every new message updates the profile; every product search reads from it. The profile is the source of truth — not the raw message history.
This distinction matters. Passing the entire message history to the language model on every turn is expensive and fragile — models lose track of early details in long contexts, and you can't inspect what the model thinks it knows. Structured context gives you consistency, debuggability, and a far smaller surface area for errors.
Stage 3: Hybrid Retrieval
Finding the right products requires two fundamentally different search strategies working in parallel.
Semantic search converts the shopper's query and the product catalogue into vector embeddings and ranks products by similarity. It captures meaning rather than keywords — "something for a beach wedding" retrieves flowing, lightweight fabrics in warm colours even if none of those exact words appear in the product description. We use cosine similarity with a minimum threshold to filter low-confidence matches, and retrieve the top 15 candidates before any reranking.
Native keyword search handles what semantic search misses: exact SKUs, brand names, specific fabric terms, and queries where the shopper is searching precisely rather than describing. We run native search in parallel and merge results by product ID. Products appearing in both result sets rank highest — the signal of two independent retrieval methods agreeing is more reliable than either alone.
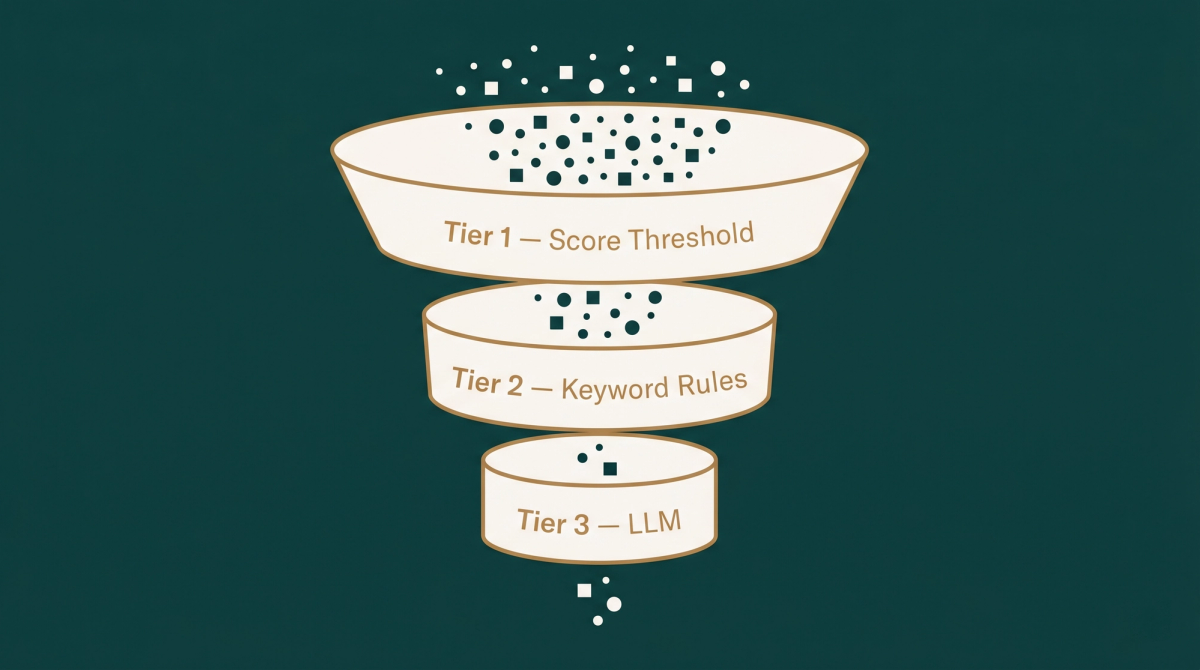
Stage 4: The Three-Tier Relevance Gate
Raw retrieval results are never good enough to show directly. A product catalogue contains accessories, packaging, and adjacent items that are semantically near but contextually wrong — a shopper asking for sarees should not receive saree care labels or blouse fabric.
Our three-tier gate filters these out without burning language model tokens on every query. Tier one is a vector score threshold — anything below the minimum similarity score is dropped with no LLM involvement. Tier two applies keyword heuristics to detect accessory-type products and flag them for removal. Only tier three, for genuinely ambiguous cases, makes a language model call.
The vast majority of filtering decisions happen in tiers one and two — deterministic, instantaneous, free. The language model handles only the hard cases where human-like judgement is genuinely required. This design reduced our LLM call volume dramatically compared to a naive approach that routes every query through the model.
Stage 5: Response Generation and Hallucination Guards
Language models have a tendency to fill gaps with plausible-sounding details that aren't true. In product search, this is dangerous: a model might invent a price range, recommend an out-of-stock product, or describe a fabric the product doesn't actually have.
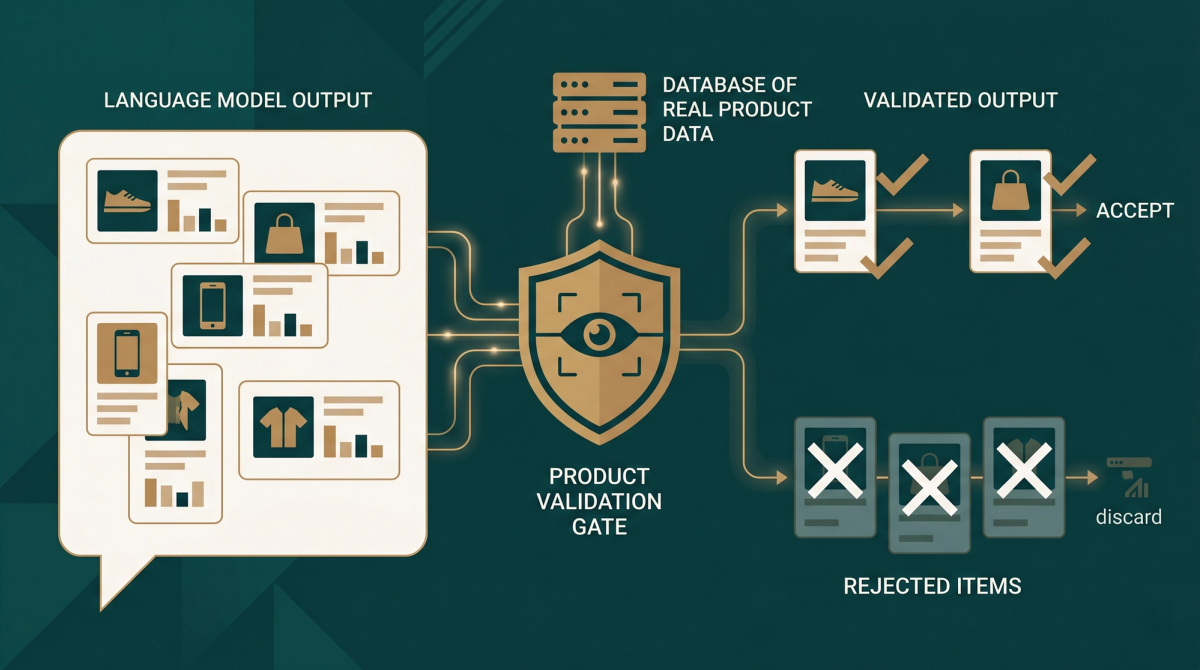
We validate every response server-side before it reaches the shopper. If the model references a price limit the shopper didn't state, we null it. If the model recommends a product not in the retrieved set, we remove it. Budget constraints mentioned by the shopper are verified against actual Shopify price data — not the model's estimate. These guards run as post-processing code, not as prompts. Code that checks the model's work against ground truth and corrects it before delivery.
The Problems We Didn't See Coming
Three challenges surprised us during development — not the AI hard problems, but the product complexity problems.
Gender context ambiguity. A shopper asking for "something for my husband" and a shopper asking for themselves require completely different product sets. But the cue is often implicit — "for a wedding" doesn't tell you whose wedding or what role you're playing. We had to design explicit gender context extraction and persist it in the session profile, updating it whenever new cues appeared.
Code-switching queries. South Asian shoppers frequently mix English and Hindi in the same message — "mujhe kuch dikhao for the reception" or "silk saree with minimal work." Our embedding approach needed to handle this gracefully across languages, which influenced our choice of multilingual-capable models over English-only alternatives.
Long-session drift. In a long conversation, early preferences can contradict later ones. A shopper might say "budget under two thousand" and then, after seeing options, say "okay show me something nicer." The session profile needs to know which signal is more recent and give it priority — without discarding earlier context that might still be relevant.
What Actually Made It Work
The single most important architectural decision: we treat the conversation as a structured object, not a string of messages.
Most conversational AI systems pass the message history to the language model and trust it to infer context. This is fast to build and fragile in production. The session profile we maintain is a typed data structure with named fields. Budget is a number. Gender is an enum. Occasion is a persisted string. When the model generates a response, it reads the profile — not the history. When guards validate the response, they check against the profile — not the model's interpretation of the history.
Structured context also makes debugging tractable. When a recommendation is wrong, we inspect the session profile, identify which field was incorrect or missing, and fix the extraction logic precisely. We don't have to prompt-engineer our way to different behaviour and hope it holds.
What's Next
The current pipeline handles product discovery well. The next frontier is post-discovery: helping shoppers compare options, understand fit, and complete the purchase without leaving the conversation. We're also expanding the proactive layer — triggers that surface recommendations before the shopper asks, based on the page they're viewing and the context they've already provided.
The architecture will stay the same: structured context, layered fallbacks, hybrid retrieval, and guards that keep the model honest. The specific capabilities will grow around that foundation.
Try it free
Ready to put WisdomChat to work?
Install WisdomChat on your Shopify store and watch it turn browsers into buyers.
Install WisdomChat